Update: Due to new personal commitments and more work commitments in 2021, I wasn’t able to make much progress with my weekly C# A-Z series on dev.to/shahedc. For now, I’ll focus on some new content for my regular blog (this blog, WakeUpAndCode.com) and hope to revisit the A-Z series with .NET 6.
Original Post:
I published my first ASP .NET Core A-Z series on WakeUpAndCode.com back in 2019, from January to June 2019. I followed this with a new A-Z series in 2020, simultaneously mirroring the posts on dev.to as well.
Going forward, my next A-Z series will cover 26 topics covering various C# language features. The C# A-Z series will be featured exclusively on my dev.to site under the .NET org:
Meanwhile, this site (WakeUpAndCode.com) will continue to feature new ASP .NET Core content based on .NET 5, Blazor and more! To get a sneak peak of what’s to come, check out my guest appearance on the .NET Docs Show (livestreamed Dec 7, 2020). You may jump ahead to 58:05 in the video for the sneak peek:
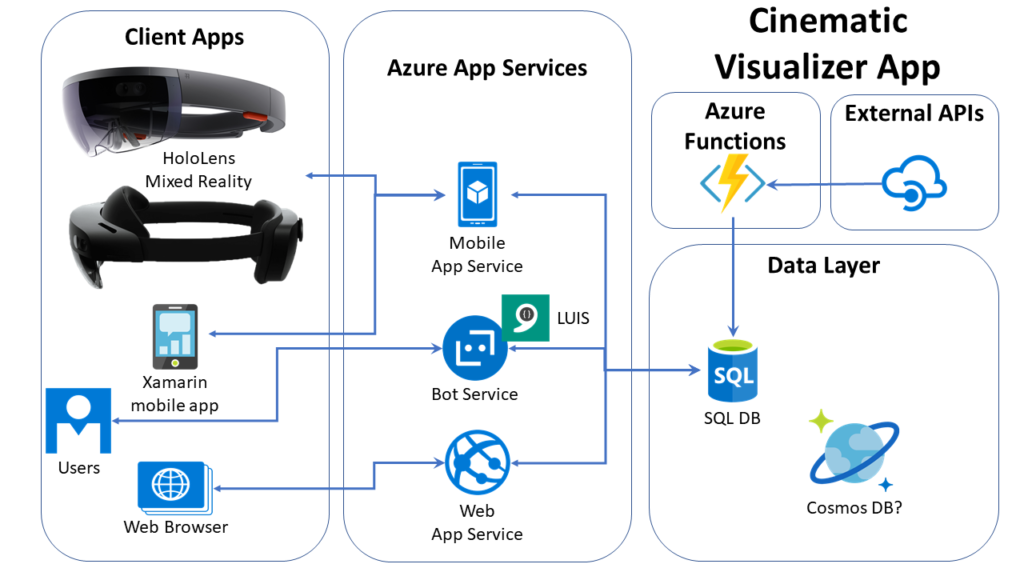
The above video teases my upcoming cinematic visualizer app, which will allow the end user to connect the dots within a cinematic universe, e.g. the Marvel Cinematic Universe. The source code will allow any .NET developer to learn more about C# and .NET 5, ASP .NET Core, Entity Framework, Azure App Service, Bot Framework, Azure Functions, and more!
High-Level Diagram of Cinematic Visualizer
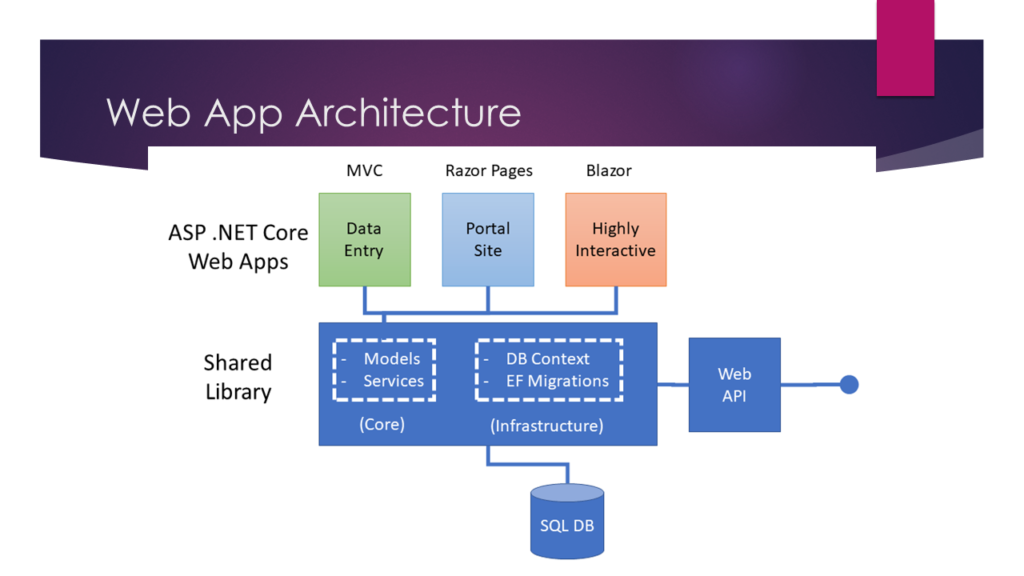
The goal of the web app is to make use of all 3 project styles available in ASP .NET Core:
MVC (Model View Controller)
Razor Pages
Blazor
ASP .NET Core web architecture
Developers frequently ask the developer community (and Microsoft) whether a particular web project type is preferred over the other. Last year’s blog series built upon the NetLearner web app by duplicating identical functionality across all three project types. This year, the cinematic visualizer app will attempt to use each project type of something specific.
MVC for data entry
Razor Pages for the Portal site
Blazor for the highly interactive portion
The above choices aren’t necessarily prescriptive for the type of web apps they will demonstrate. However, they should provide a starting point when developing ASP .NET Core web applications.
As promised, below is the initial release of the ASP .NET Core 3.1 A-Z ebook. This combines the 26 blog posts from the series of ASP .NET Core articles on this website.
ASP .NET Core 3.1 A-Z ebook cover
You can find the complete ebook on GitHub using one of the links below:
The cover image was generated using the Canva mobile app
The 2020 eBook is still a work in progress 🙂
I’m using my Worker Service sample to auto-generate Word documents from each blog post by converting each article’s HTML into Word format using MariGold.OpenXHTML
After some tweaking, images have been manually resized using a Macro in the Word document. Automatic resizing doesn’t seem to work between HTML to Word conversions, but feel free to submit a Pull Request if you have suggestions on how to fix it.
Animated GIF images don’t work in the ebook, so a link to each original source has been included where they appear in a few chapters.
This is the twenty-fifth of a new series of posts on ASP .NET Core 3.1 for 2020. In this series, we’ll cover 26 topics over a span of 26 weeks from January through June 2020, titled ASP .NET Core A-Z! To differentiate from the 2019 series, the 2020 series will mostly focus on a growing single codebase (NetLearner!) instead of new unrelated code snippets week.
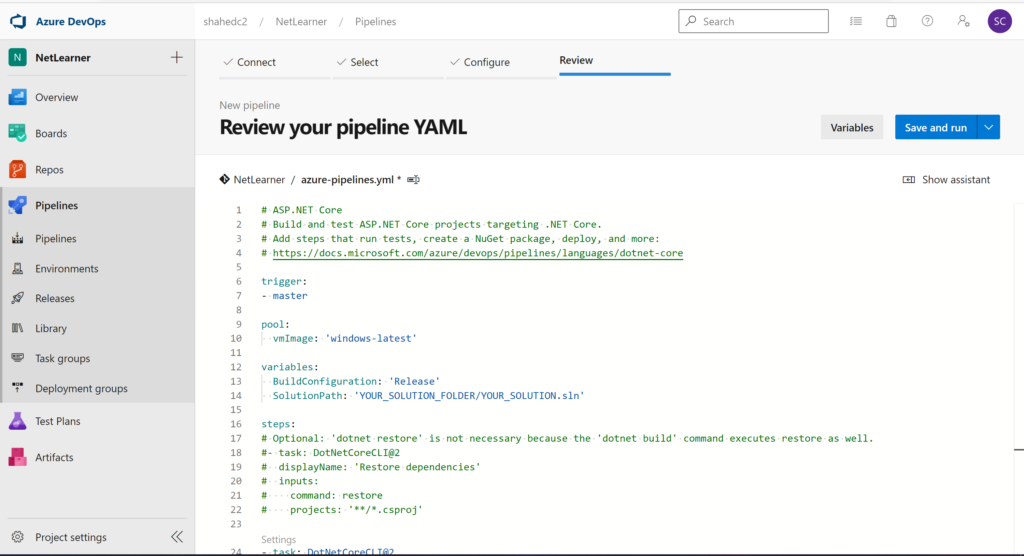
If you haven’t heard of it yet, YAML is yet another markup language. No really, it is. YAML literally stands for Yet Another Markup Language. If you need a reference for YAML syntax and how it applies to Azure DevOps Pipelines, check out the official docs:
NOTE: Before using the aforementioned YAML sample in an Azure DevOps project, please replace any placeholder values and rename the file to remove the .txt suffix.
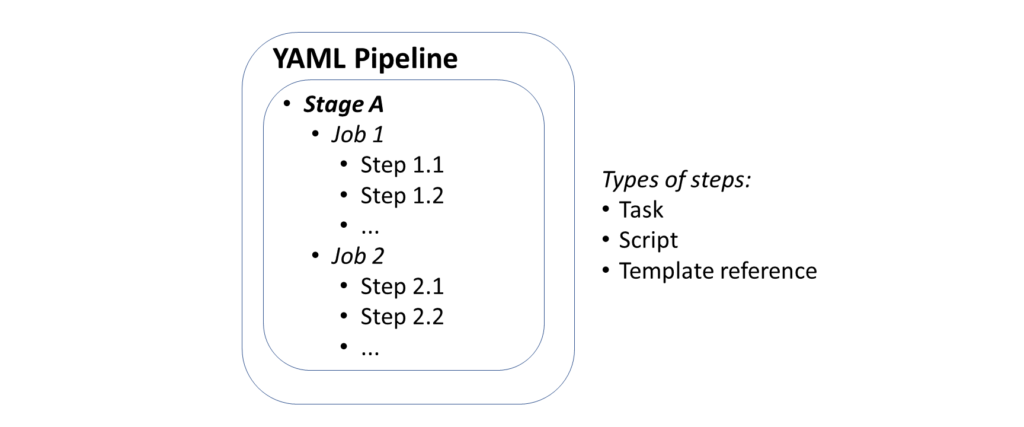
In the context of Azure DevOps, you can use Azure Pipelines with YAML to make it easier for you set up a CI/CD pipeline for Continuous Integration and Continuous Deployment. This includes steps to build and deploy your app. Pipelines consist of stages, which consist of jobs, which consists of steps. Each step could be a script or task. In addition to these options, a step can also be a reference to an external template to make it easier to create your pipelines.
DevOps Pipeline in YAML
Getting Started With Pipelines
To get started with Azure Pipelines in Azure DevOps:
Select your repo, e.g. a specific GitHub repository
Configure your YAML
Review your YAML and Run it
From here on forward, you may come back to your YAML here, edit it, save it, and run as necessary. You’ll even have the option to commit your YAML file “azure-pipelines.yml” into your repo, either in the master branch or in a separate branch (to be submitted as a Pull Request that can be merged).
YAML file in Azure DevOps
If you need more help getting started, check out the official docs and Build 2019 content at:
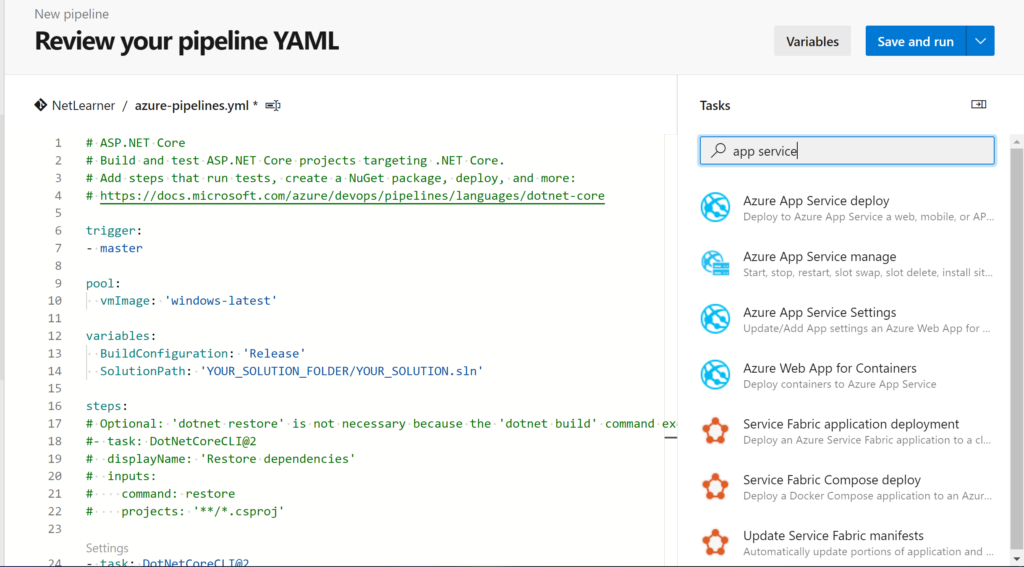
To add pre-written snippets to your YAML, you may use the Task Assistant side panel to insert a snippet directly into your YAML file. This includes tasks for .NET Core builds, Azure App Service deployment and more.
Task Assistant in Azure DevOps
OS/Environment and Runtime
From the sample repo, take a look at the sample YAML code sample “azure-pipelines.yml.txt“. Near the top, there is a definition for a “pool” with a “vmImage” set to ‘windows-latest’.
pool:
vmImage: 'windows-latest'
If I had started off with the default YAML pipeline configuration for a .NET Core project, I would probably get a vmImage value set to ‘ubuntu-latest’. This is just one of many possible values. From the official docs on Microsoft-hosted agents, we can see that Microsoft’s agent pool provides at least the following VM images across multiple platforms, e.g.
Windows Server 2019 with Visual Studio 2019 (windows-latest OR windows-2019)
Windows Server 2016 with Visual Studio 2017 (vs2017-win2016)
Ubuntu 18.04 (ubuntu-latest OR ubuntu-18.04)
Ubuntu 16.04 (ubuntu-16.04)
macOS X Mojave 10.14 (macOS-10.14)
macOS X Catalina 10.15 (macOS-latest OR macOS-10.15)
In addition to the OS/Environment, you can also set the .NET Core runtime version. This may come in handy if you need to explicitly set the runtime for your project.
Once you’ve set up your OS/environment and runtime, you can restore (dependencies) and build your project. Restoring dependencies with a command is optional since the Build step will take care of the Restore as well. To build a specific configuration by name, you can set up a variable first to define the build configuration, and then pass in the variable name to the build step.
variables:
BuildConfiguration: 'Release'
SolutionPath: 'YOUR_SOLUTION_FOLDER/YOUR_SOLUTION.sln'
steps:
# Optional: 'dotnet restore' is not necessary because the 'dotnet build' command executes restore as well.
#- task: DotNetCoreCLI@2
# displayName: 'Restore dependencies'
# inputs:
# command: restore
# projects: '**/*.csproj'
- task: DotNetCoreCLI@2
displayName: 'Build web project'
inputs:
command: 'build'
projects: $(SolutionPath)
In the above snippet, the BuildConfiguration is set to ‘Release’ so that the project is built for its ‘Release’ configuration. The displayName is a friendly name in a text string (for any step) that may include variable names as well. This is useful for observing logs and messages during troubleshooting and inspection.
NOTE: You may also use script steps to make use of dotnet commands with parameters you may already be familiar with, if you’ve been using .NET Core CLI Commands. This makes it easier to run steps without having to spell everything out.
steps:
- task: DotNetCoreCLI@2
inputs:
command: restore
projects: '**/*.csproj'
feedsToUse: config
nugetConfigPath: NuGet.config
externalFeedCredentials: <Name of the NuGet service connection>
Note that you can set your own values for an external NuGet feed to restore dependencies for your project. Once restored, you may also customize your build steps/tasks.
Although unit testing is not required for a project to be compiled and deployed, it is absolutely essential for any real-world application. In addition to running unit tests, you may also want to measure your code coverage for those unit tests. All these are possible via YAML configuration.
From the official docs, here is a snippet to run your unit tests, that is equivalent to a “dotnet test” command for your project:
Once again, the above snippet uses the “dotnet test” command, but also adds the –collect option to enable the data collector for your test run. The text string value that follows is a friendly name that you can set for the data collector. For more information on “dotnet test” and its options, check out the docs at:
The above snippet runs a “dotnet publish” command with the proper configuration setting, followed by an output location, e.g. Build.ArtifactStagingDirectory. The value for the output location is one of many predefined build/system variables, e.g. System.DefaultWorkingDirectory, Build.StagingDirectory, Build.ArtifactStagingDirectory, etc. You can find out more about these variables from the official docs:
Note that there is a placeholder text string for the Azure Subscription ID. If you use the Task Assistant panel to add a “Azure App Service Deploy” snippet, you will be prompted to select your Azure Subscription, and a Web App location to deploy to, including deployment slots if necessary.
The PublishBuildArtifacts task uploads the package to a file container, ready for deployment. After your artifacts are ready, a zip file will become available in a named container, e.g. ‘drop’.
# Optional step if you want to deploy to some other system using a Release pipeline or inspect the package afterwards
- task: PublishBuildArtifacts@1
displayName: 'Publish Build artifacts'
inputs:
PathtoPublish: '$(Build.ArtifactStagingDirectory)'
ArtifactName: 'drop'
publishLocation: 'Container'
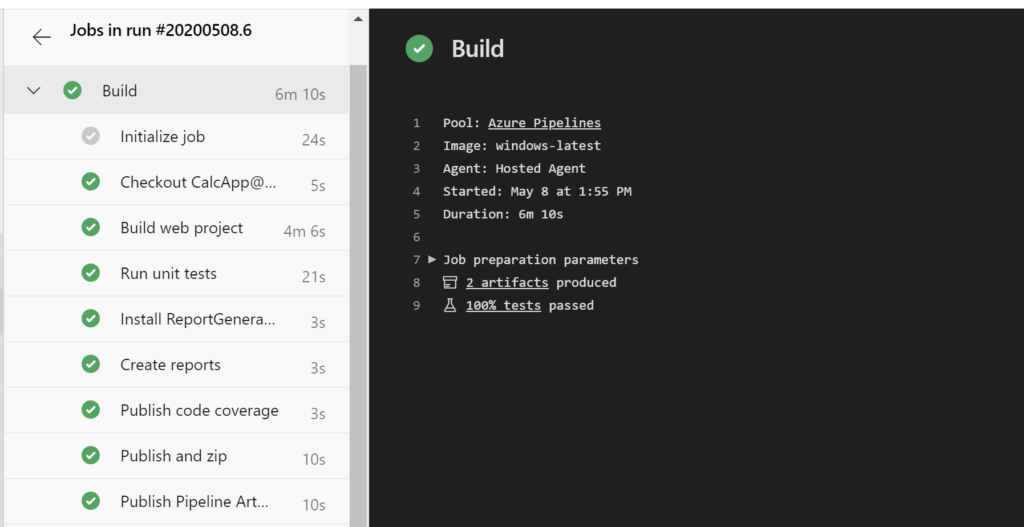
You may use the Azure DevOps portal to inspect the progress of each step and troubleshoot any failed steps. You can also drill down into each step to see the commands that are running in the background, followed by any console messages.
Azure DevOps success messages
NOTE: to set up a release pipeline with multiple stages and optional approval conditions, check out the official docs at:
Now that you’ve set up your pipeline, how does this all get triggered? If you’ve taken a look at the sample YAML file, you will notice that the first command includes a trigger, followed by the word “master”. This ensures that the pipeline will be triggered every time code is pushed to the corresponding code repository’s master branch. When using a template upon creating the YAML file, this trigger should be automatically included for you.
trigger:- master
To include more triggers, you may specify triggers for specific branches to include or exclude.
Finally here are some tips and tricks when using YAML to set up CI/CD using Azure Pipelines:
Snippets: when you use the Task Assistant panel to add snippets into your YAML, be careful where you are adding each snippet. It will insert it wherever your cursor is positioned, so make sure you’ve clicked into the correction location before inserting anything.
Order of tasks and steps: Verify that you’ve inserted (or typed) your tasks and steps in the correct order. For example: if you try to deploy an app before publishing it, you will get an error.
Indentation: Whether you’re typing your YAML or using the snippets (or some other tool), use proper indentation. You will get syntax errors of the steps and tasks aren’t indented correctly.
Proper Runtime/OS: Assign the proper values for the desired runtime, environment and operating system.
Publish: Don’t forget to publish before attempting to deploy the build.
Artifacts location: Specify the proper location(s) for artifacts when needed.
Authorize Permissions: When connecting your Azure Pipeline to your code repository (e.g. GitHub repo) and deployment location (e.g. Azure App Service), you will be prompted to authorize the appropriate permissions. Be aware of what permissions you’re granting.
Private vs Public: Both your Project and your Repo can be private or public. If you try to mix and match a public Project with a private Repo, you may get the following warning message: “You selected a private repository, but this is a public project. Go to project settings to change the visibility of the project.”
This is the twenty-fourth of a new series of posts on ASP .NET Core 3.1 for 2020. In this series, we’ll cover 26 topics over a span of 26 weeks from January through June 2020, titled ASP .NET Core A-Z! To differentiate from the 2019 series, the 2020 series will mostly focus on a growing single codebase (NetLearner!) instead of new unrelated code snippets week.
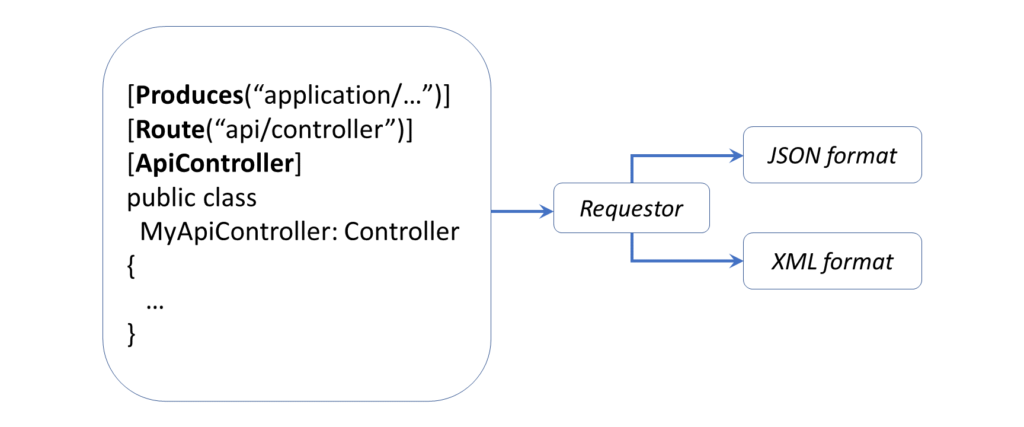
XML (eXtensible Markup Language) is a popular document format that has been used for a variety of applications over the years, including Microsoft Office documents, SOAP Web Services, application configuration and more. JSON (JavaScript Object Notation) was derived from object literals of JavaScript, but has also been used for storing data in both structured and unstructured formats, regardless of the language used. In fact, ASP .NET Core applications switched from XML-based .config files to JSON-based .json settings files for application configuration.
Returning XML/JSON format from a Web API
Returning JsonResult and IActionResult
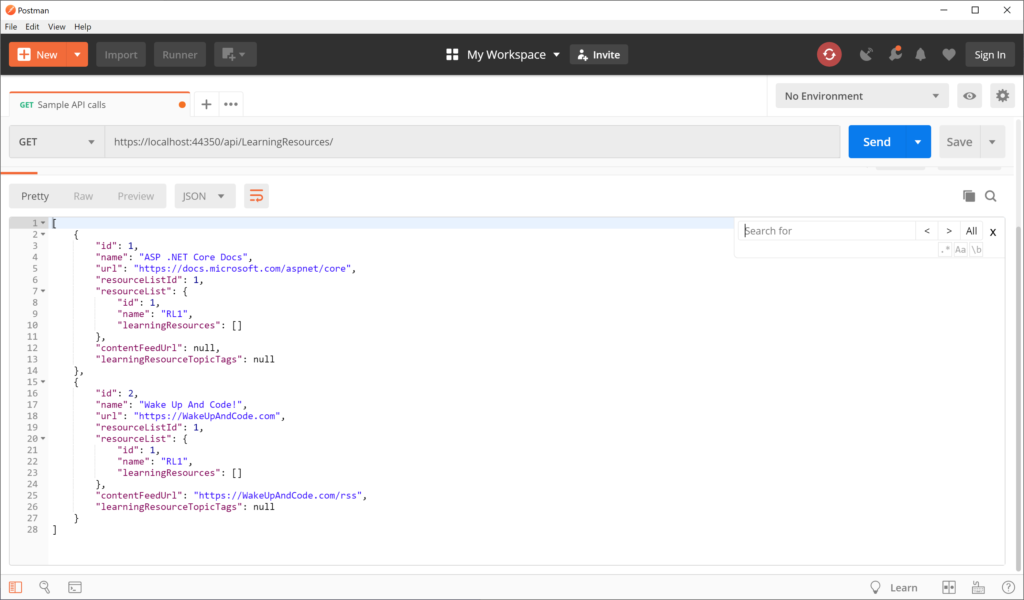
Before we get into XML output for your Web API, let’s start off with JSON output first, and then we’ll get to XML. If you run the Web API sample project in the NetLearner repository, you’ll notice a LearningResourcesController.cs file that represents a “Learning Resources Controller” that exposes API endpoints. These endpoints can serve up both JSON and XML results of Learning Resources, i.e. blog posts, tutorials, documentation, etc.
Run the application and navigate to the following endpoint in an API testing tool, e.g. Postman:
// GET: api/LearningResources
[HttpGet]
public JsonResult Get()
{
return new JsonResult(_sampleRepository.LearningResources());
}
In this case, the Json() method returns a JsonResult object that serializes a list of Learning Resources. For simplicity, the _sampleRepository object’s LearningResources() method (in SampleRepository.cs) returns a hard-coded list of LearningResource objects. Its implementation here isn’t important, because you would typically retrieve such values from a persistent data store, preferably through some sort of service class.
public List<LearningResource> LearningResources()
{
...
return new List<LearningResource>
{
new LearningResource
{
Id= 1,
Name= "ASP .NET Core Docs",
Url = "https://docs.microsoft.com/aspnet/core",
...
},
...
}
}
The JSON result looks like the following, where a list of learning resources are returned:
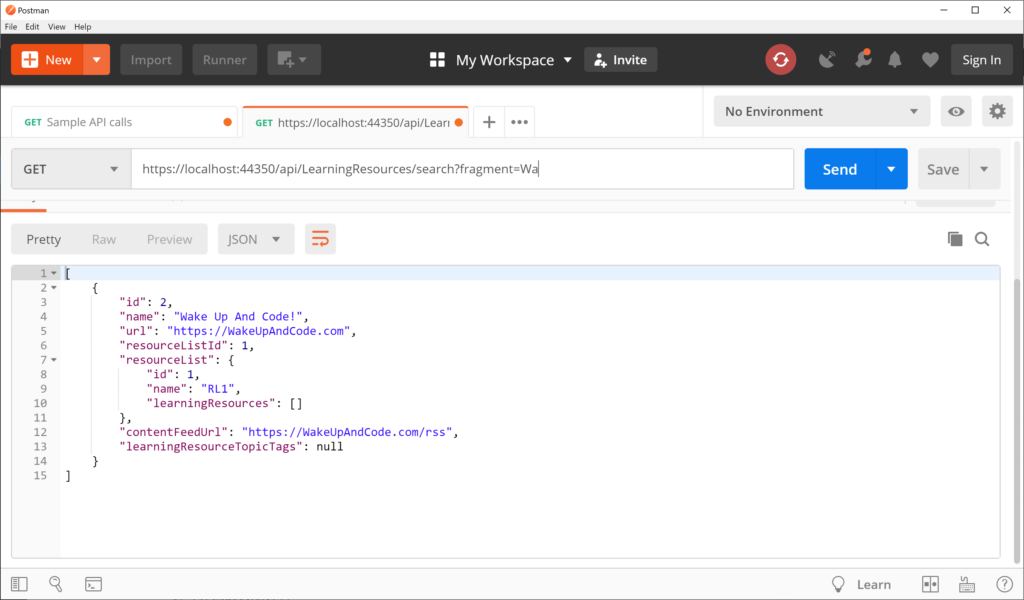
Instead of specifically returning a JsonResult, you could also return a more generic IActionResult, which can still be interpreted as JSON. Run the application and navigate to the following endpoint, to include the action method “search” folllowed by a QueryString parameter “fragment” for a partial match.
This triggers a GET request by calling the LearningResourceController‘s Search() method, with its fragment parameter set to “Wa” for a partial text search:
// GET: api/LearningResources/search?fragment=Wa
[HttpGet("Search")]
public IActionResult Search(string fragment)
{
var result = _sampleRepository.GetByPartialName(fragment);
if (!result.Any())
{
return NotFound(fragment);
}
return Ok(result);
}
In this case, the GetByPartialName() method returns a List of LearningResources objects that are returned as JSON by default, with an HTTP 200 OK status. In case no results are found, the action method will return a 404 with the NotFound() method.
An overloaded version of the Get() method takes in a “listName” string parameter to filter results by a list name for each learning resource in the repository. Instead of returning a JsonResult or IActionResult, this one returns a complex object (LearningResource) that contains properties that we’re interested in.
// GET api/LearningResources/RL1
[HttpGet("{listName}")]
public LearningResource Get(string listName)
{
return _sampleRepository.GetByListName(listName);
}
The GetByListName() method in the SampleRepository.cs class simply checks for a learning resource by the listName parameter and returns the first match. Again, the implementation is not particularly important, but it illustrates how you can pass in parameters to get back JSON results.
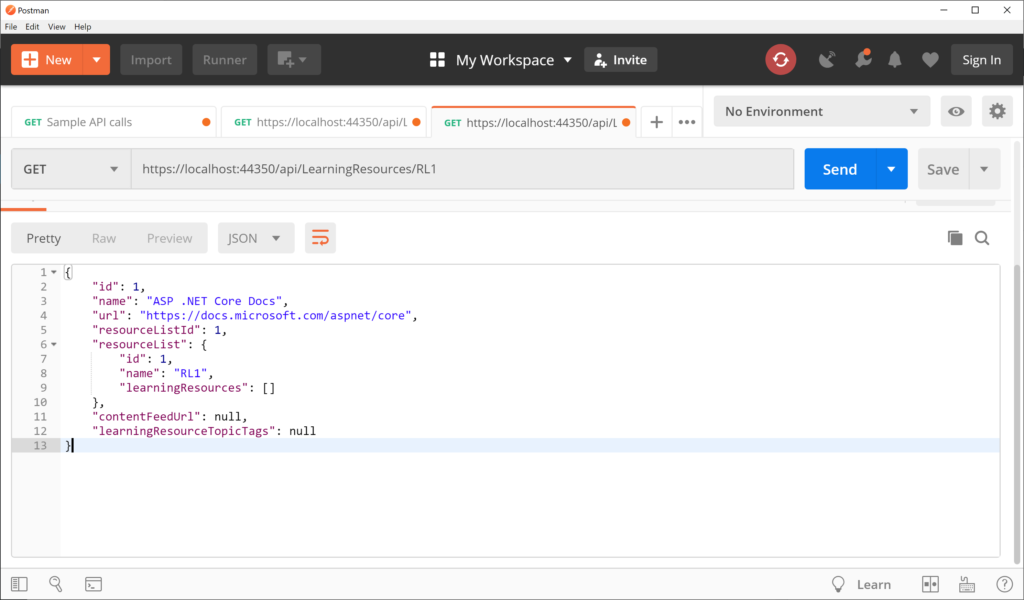
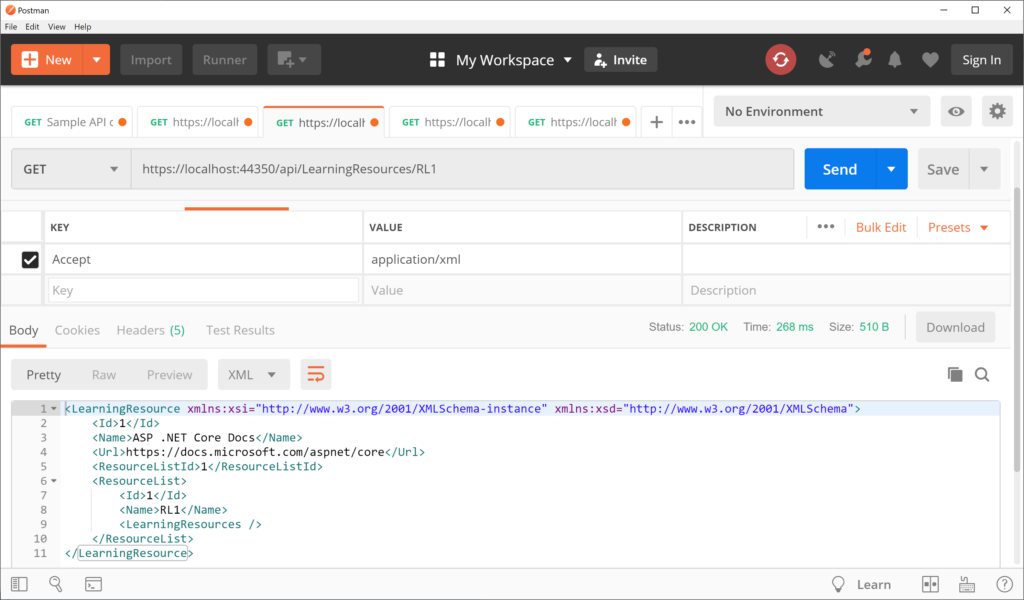
While the application is running, navigate to the following endpoint:
https://localhost:44350/api/LearningResources/RL1
Sample JSON data with property filter
This triggers another GET request by calling the LearningResourcesController‘s overloaded Get() method, with the listName parameter. When passing the list name “RL1”, this returns one item, as shown below:
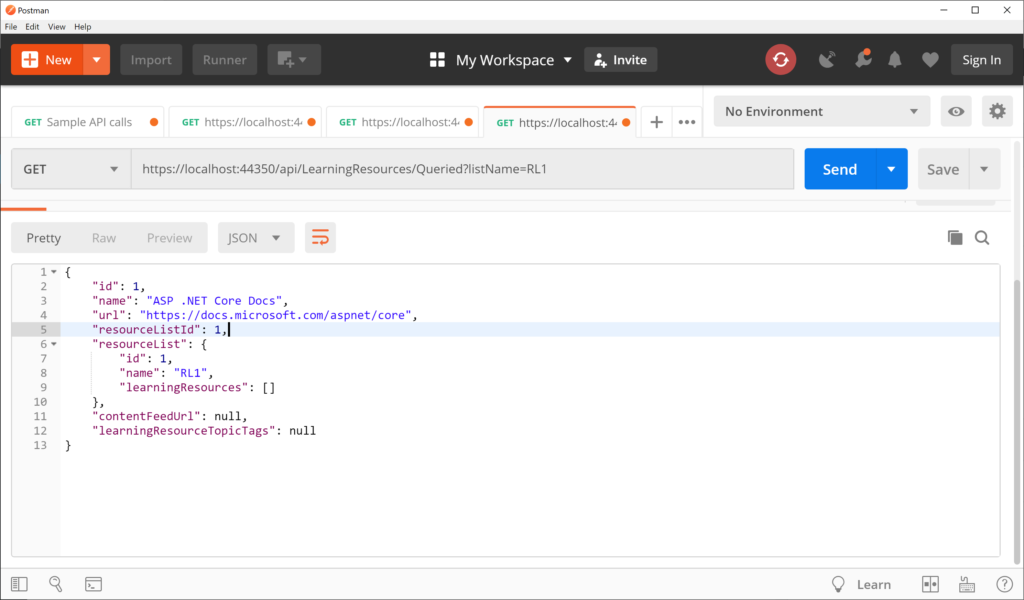
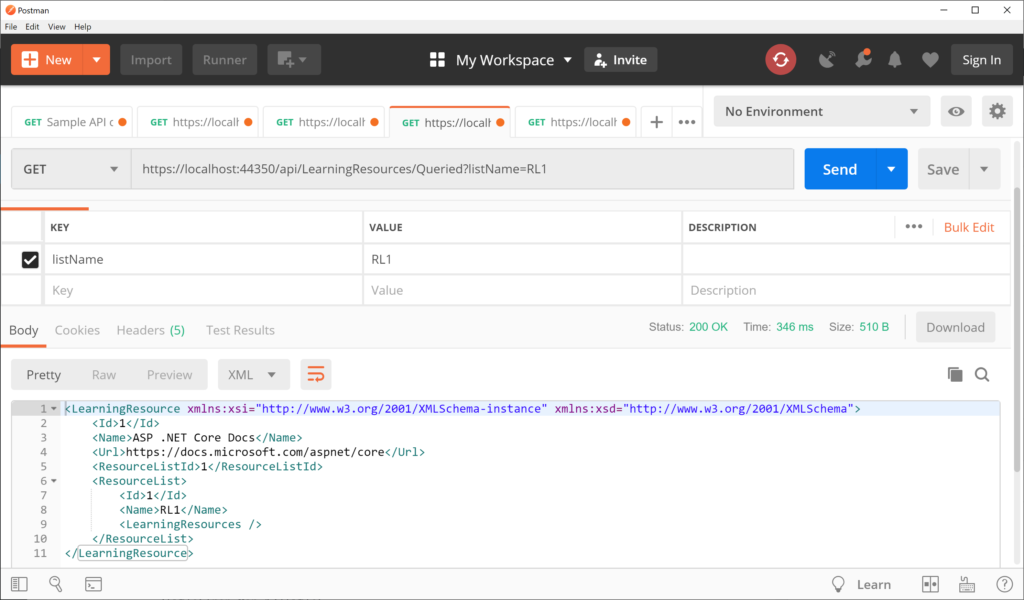
Another example with a complex result takes in a similar parameter via QueryString and checks for an exact match with a specific property. In this case the Queried() action method calls the repository’s existing GetByListName() method to find a specific learning resource by its matching list name.
This triggers a GET request by calling the LearningResourcesController‘s Queried() method, with the listName parameter. When passing the list name “RL1”, this returns one item, as shown below:
As you can see, the above result is in JSON format for the returned object.
XML Output
Wait a minute… with all these JSON results, when will we get to XML output? Not to worry, there are multiple ways to get XML results while reusing the above code. First, update your Startup.cs file’s ConfigureServices() to include a call to services.AddControllers().AddXmlSeralizerFormatters():
public void ConfigureServices(IServiceCollection services)
{
...
services.AddControllers()
.AddXmlSerializerFormatters();
...
}
In Postman, set the request’s Accept header value to “application/xml” before requesting the endpoint, then run the application and navigate to the following endpoint once again:
https://localhost:44350/api/LearningResources/RL1
XML-formatted results in Postman without code changes
Since the action method returns a complex object, the result can easily be switched to XML simply by changing the Accept header value. In order to return XML using an IActionResult method, you should also use the [Produces] attribute, which can be set to “application/xml” at the API Controller level.
[Produces("application/xml")]
[Route("api/[controller]")]
[ApiController]
public class LearningResourcesController : ControllerBase
{
...
}
Then revisit the following endpoint, calling the search action method with the fragment parameter set to “ir”:
At this point, it is no longer necessary to set the Accept header to “application/xml” (in Postman) during the request, since the [Produces] attribute is given priority over it.
XML-formatted output using Produces attribute
This should produces the following result , with a LearningResource object in XML:
As for the first Get() method returning JsonResult, you can’t override it with the [Produces] attribute or the Accept header value to change the result to XML format.
This is the twenty-third of a new series of posts on ASP .NET Core 3.1 for 2020. In this series, we’ll cover 26 topics over a span of 26 weeks from January through June 2020, titled ASP .NET Core A-Z! To differentiate from the 2019 series, the 2020 series will mostly focus on a growing single codebase (NetLearner!) instead of new unrelated code snippets week.
NOTE: The Worker Service sample is a meta project that generates Word documents from blog posts, to auto-generate an ebook from this blog series. You can check out the code in the following experimental subfolder, merged from a branch:
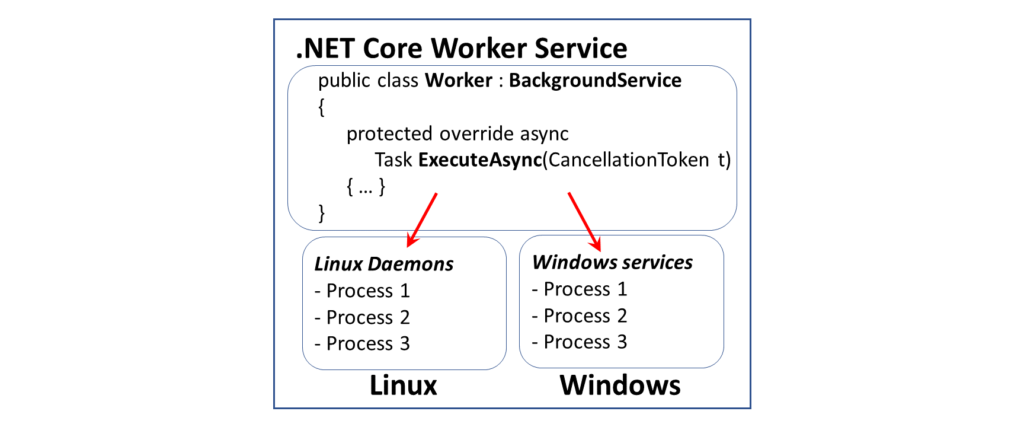
When you think of ASP .NET Core, you probably think of web application backend code, including MVC and Web API. MVC Views and Razor Pages also allow you to use backend code to generate frontend UI with HTML elements. The all-new Blazor goes one step further to allow client-side .NET code to run in a web browser, using WebAssembly. And finally, we now have a template for Worker Service applications.
Released with ASP .NET Core 3.0, the new project type was introduced in ASP .NET Core early previews. Although the project template was initially listed under the Web templates, it has since been relocated one level up in the New Project wizard. This is a great way to create potentially long-running cross-platform services in .NET Core. This article covers the Windows operating system.
Cross-platform .NET Core Worker Service
New Worker Service Project
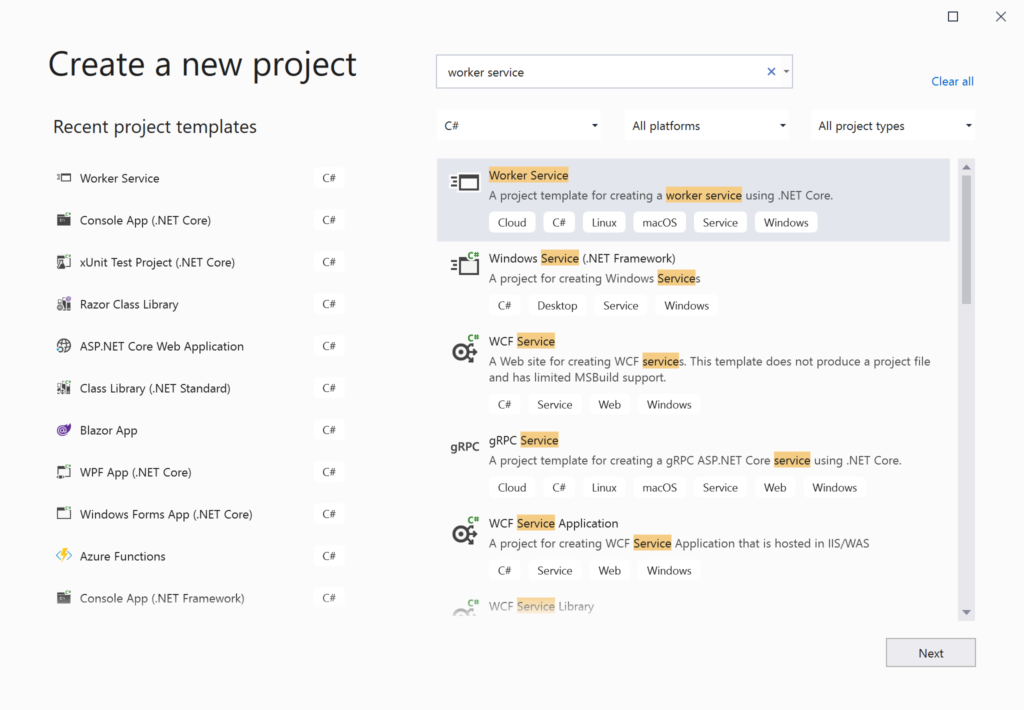
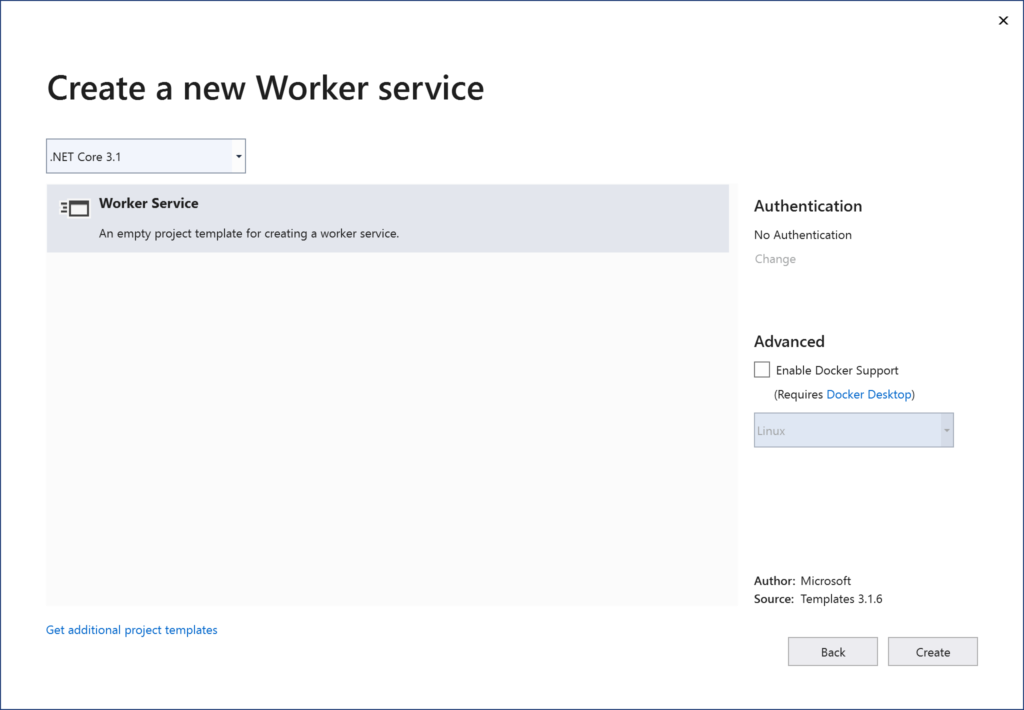
The quickest way to create a new Worker Service project in Visual Studio 2019 is to use the latest template available with .NET Core 3.1. You may also use the appropriate dotnet CLI command.
Launch Visual Studio and select the Worker service template as shown below. After selecting the location, verify the version number (e.g. .NET Core 3.1) to create the worker service project.
Worker Service template in Visual Studio 2019Worker Service on .NET Core 3.1
To use the Command Line, simply use the following command:
> dotnet new worker -o myproject
where -o is an optional flag to provide the output folder name for the project.
You can learn more about this template at the following location:
The Program.cs class contains the usual Main() method and a familiar CreateHostBuilder() method. This can be seen in the snippet below:
public class Program
{
public static void Main(string[] args)
{
CreateHostBuilder(args).Build().Run();
}
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureServices(hostContext, services =>
{
services.AddHostedService<Worker>();
});
}
Things to note:
The Main method calls the CreateHostBuilder() method with any passed parameters, builds it and runs it.
As of ASP .NET Core 3.0, the Web Host Builder has been replaced by a Generic Host Builder. The so-called Generic Host Builder was covered in an earlier blog post in this series.
CreateHostBuilder() creates the host and configures it by calling AddHostService<T>, where T is an IHostedService, e.g. a worker class that is a child of BackgroundService
The worker class, Worker.cs, is defined as shown below:
public class Worker : BackgroundService
{
// ...
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
// do stuff here
}
}
Things to note:
The worker class implements the BackgroundService class, which comes from the namespace Microsoft.Extensions.Hosting
The worker class can then override the ExecuteAsync() method to perform any long-running tasks.
In the sample project, a utility class (DocEngine.cs) is used to convert a web page (e.g. a blog post or article) into a Word document for offline viewing. Fun fact: when this A-Z series wraps up, the blog posts will be assembled into a free ebook, by using this DocMaker, which uses some 3rd-party NuGet packages to generate the Word document.
Logging in a Worker Service
Logging in ASP .NET Core has been covered in great detail in an earlier blog post in this series. To get a recap, take a look at the following writeup:
NOTE: Run Powershell in Administrator Mode before running the commands below.
Before you continue, add a call to UseWindowsService() in your Program class, or verify that it’s already there. To call UseWindowsService(), the following package must be installed in your project: Microsoft.Extensions.Hosting.WindowsServices
The official announcement and initial document referred to UseServiceBaseLifetime() in an earlier preview. This method was renamed to UseWindowsService() before release.
According to the code documentation, UseWindowsService() does the following:
Sets the host lifetime to WindowsServiceLifetime
Sets the Content Root
Enables logging to the event log with the application name as the default source name
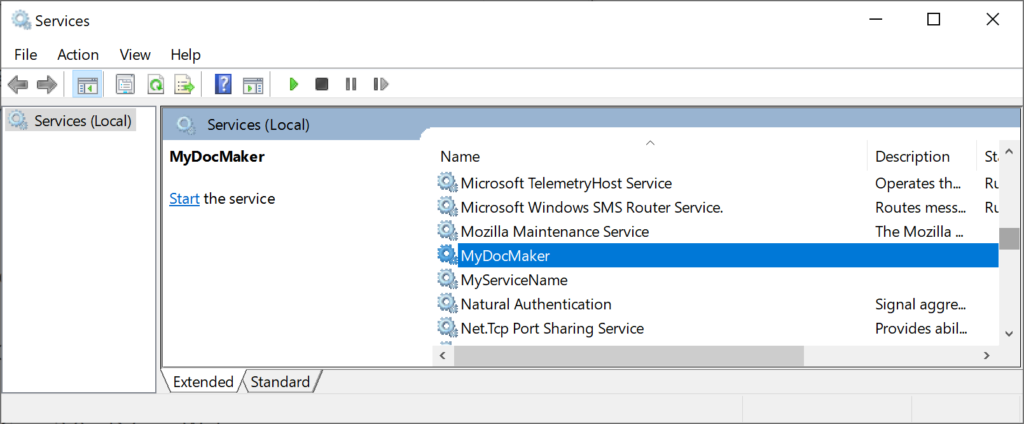
You can run the Worker Service in various ways:
Build and Debug/Run from within Visual Studio.
Publish to an exe file and run it
Run the sc utility (from Windows\System32) to create a new service
To publish the Worker Service as an exe file with dependencies, run the following dotnet command:
dotnet publish -o C:\path\to\project\pubfolder
The -o parameter can be used to specify the path to a folder where you wish to generate the published files. It could be the path to your project folder, followed by a new subfolder name to hold your published files, e.g. pubfolder. Make a note of your EXE name, e.g. MyProjectName.exe but omit the pubfolder from your source control system.
To create a new service, run sc.exe from your System32 folder and pass in the name of the EXE file generated from the publish command.